Doğal dil işleme (NLP) teknolojilerinin gelişmesiyle birlikte, belgeleri anlamak ve kullanıcı sorularına yanıt vermek için chatbotlar giderek daha popüler hale geliyor.
Adımlar
- PDF Dosyasını Metne Dönüştürme
- Metni Parçalara Ayırma ve Overlap Kullanma
- Embedding Oluşturma
- FAISS Kullanarak Vektör Veritabanı Oluşturma
- Sorgu İşleme ve Yanıt Oluşturma
- Chatbot’u Entegre Etme
RAG Mimarisi :
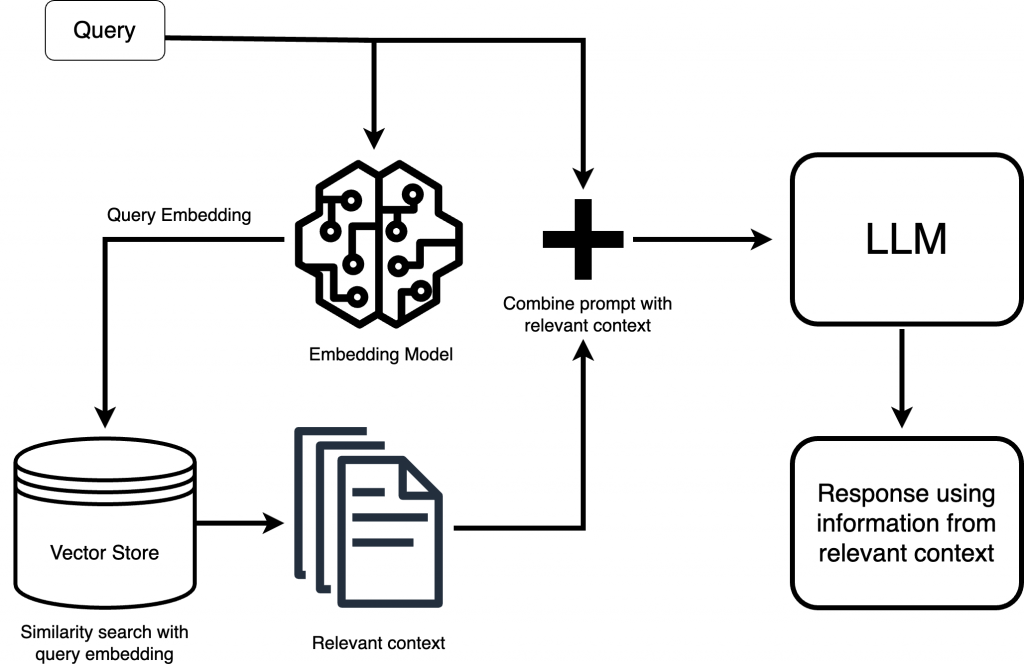
Kaynak : https://www.clarifai.com/hs-fs/hubfs/rag-query-drawio%20(1)-png-2.png?width=2056&height=1334&name=rag-query-drawio%20(1)-png-2.png
1. PDF Dosyasını Metne Dönüştürme
Öncelikle, PDF dosyasındaki metni çıkarmamız gerekiyor. Bunun için PyMuPDF kütüphanesini kullanabiliriz.
import fitz # PyMuPDF
def extract_text_from_pdf(pdf_path):
document = fitz.open(pdf_path)
text = ""
for page_num in range(len(document)):
page = document.load_page(page_num)
text += page.get_text()
return text
pdf_text = extract_text_from_pdf('your_file.pdf')
2. Metni Parçalara Ayırma ve Overlap Kullanma
Metni belirli uzunluklarda parçalara ayırarak ve overlap kullanarak daha anlamlı parçalara sahip olabiliriz.
def split_text_with_overlap(text, max_length=500, overlap_length=50):
sentences = text.split('. ')
chunks = []
current_chunk = []
current_length = 0
for sentence in sentences:
sentence_length = len(sentence.split())
if current_length + sentence_length <= max_length:
current_chunk.append(sentence)
current_length += sentence_length
else:
chunks.append(' '.join(current_chunk))
overlap = current_chunk[-1].split()[-overlap_length:]
current_chunk = overlap
current_length = len(current_chunk)
chunks.append(' '.join(current_chunk))
return chunks
text_chunks = split_text_with_overlap(pdf_text)
3. Embedding Oluşturma
OpenAI’nin embedding modelini kullanarak metin parçalarını vektörlere dönüştürebiliriz.
import openai
openai.api_key = 'YOUR_API_KEY'
def get_embedding(text):
response = openai.Embedding.create(input=text, model="text-embedding-ada-002")
return response['data'][0]['embedding']
embeddings = [get_embedding(chunk) for chunk in text_chunks]
4. FAISS Kullanarak Vektör Veritabanı Oluşturma
FAISS kullanarak embedding vektörlerini saklayabilir ve hızlı arama yapabiliriz.
import faiss
import numpy as np
dimension = len(embeddings[0])
index = faiss.IndexFlatL2(dimension)
embedding_matrix = np.array(embeddings).astype('float32')
index.add(embedding_matrix)
def query_faiss(query, k=5):
query_embedding = np.array(get_embedding(query)).astype('float32').reshape(1, -1)
distances, indices = index.search(query_embedding, k)
return indices[0]
query = "PDF ile ilgili bir soru"
top_k_indices = query_faiss(query)
relevant_chunks = [text_chunks[i] for i in top_k_indices]
5. Sorgu İşleme ve Yanıt Oluşturma
Toplanan metin parçalarını kullanarak anlamlı bir yanıt oluşturmak için OpenAI’nın dil modelini kullanabiliriz.
def generate_response(relevant_chunks, query):
context = " ".join(relevant_chunks)
prompt = f"Soru: {query}\n\nKapsamlı ve detaylı bir yanıt oluşturmak için aşağıdaki bilgileri kullanın:\n\n{context}"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=150
)
return response['choices'][0]['text'].strip()
response = generate_response(relevant_chunks, query)
print(response)
6. Chatbot’u Entegre Etme
Artık chatbot‘u bir web uygulaması veya başka bir kullanıcı arayüzüne entegre edebiliriz. Örneğin, Flask veya FastAPI kullanarak bir web servisi oluşturabilirsiniz.
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/chatbot', methods=['POST'])
def chatbot():
user_query = request.json.get('query')
top_k_indices = query_faiss(user_query)
relevant_chunks = [text_chunks[i] for i in top_k_indices]
response = generate_response(relevant_chunks, user_query)
return jsonify({'response': response})
if __name__ == '__main__':
app.run()